浅谈Java开发中Redis的使用姿势
文章目录
【注意】最后更新于 March 1, 2023,文中内容可能已过时,请谨慎使用。
Redis是我们开发时最常使用的键值存储工具了,但是与诸多软件工具一样,它也有很多技巧和经验。本文就是将我了解的一些经验和教训分享出来。
使用建议
如果不谨慎使用Redis,可能浪费大量的内存,甚至性能低下。以下时 使用时的几个具体建议:
命名规范
通常一个Redis实例有16个数据库,通常你的业务并不是独立的数据库。为了与其它业务避免冲突,通常会用前缀后缀做一些区分,比如"业务名称:原始key"作为真正存储的key。但是要注意的是,Key本身是字符串,Redis的底层数据结构是SDS。从Redis3.2开始,key长度增长时,SDS占用内存空间也会增加,所以Key的长度我们要适当控制。SDS 结构中的字符串长度和元数据大小的对应关系如下表所示:
| 字符串大小(字节) | SDS结构元数据大小(字节) |
|---|---|
| 1~(2^5-1) | 1 |
| (2^5)~(2^8-1) | 1 |
| (2^8)~(2^16-1) | 1 |
| (2^16)~(2^32-1) | 1 |
| (2^32)~(2^64-1) | 1 |
避免使用 bigkey
Redis效率如此高的一个原因是,它是单线程服务的模型。如果有bigkey,读写的时候就会阻塞线程,降低redis的处理效率。bigkey有两种情况:
- 键值对的值本身就很大,超过了1MB。这通常需要业务把存储的value降低到10k以下,可以采取数据压缩的办法来减少内存占用
- 键值对的值是集合类型,而集合的元素非常多。需要业务将value控制在1万以下比较适合,必要的话就拆分集合
使用高效的序列化和压缩方法
Java有多种序列化方式,比如protostuff和kryo,比Java内置的序列化方法更高效。有时候业务还会使用XML或者JSON存储。有时候为了避免XML和JSON的体积过大,可以使用snappy或者gzip压缩后再存入Redis,可以减少60%的内存占用
使用整数对象共享池
Redis内部维护了0-9999共一万个整数对象,并且把这一万个整数作为一个共享池使用。但是也有两种情况无法使用共享池:
- 如果Redis设置了maxmemory,而且开启了LRU策略(allkeys-LRU或者volatile-LRU),就无法使用共享池,因为无法判断LRU了
- 如果集合类型的数据采用ziplist编码,而集合元素是整数u,也不能使用共享池,因为ziplist使用了紧凑的内存结构,判断整数对象的共享情况效率低下
利用Hash优化缓存
如果是同一个实体的多个属性做缓存,用同一个key的hash来存储,可以减少额外的元数据占用
尽可能减少存储的数据量
不论是string,List,Set还是Zset,底层实现都是多样的。Redis会根据数据结构中的数据量做动态调整。比如字符串,如果是少于20的整数,会直接存储在指针里;小于等于44的字符串会存储在一段连续的44长度的内存。如果你存储在这些结构里的数据量少于阈值,就可以采用更简单高效的数据结构,从而带来一定的收益。
只用来保存热数据
Redis使用的是最昂贵的内存进行存储,RDB和AOF日志持久化保存数据都只是提供数据可靠性保障的,并不能扩充容量。因此业务最好只存储热点数据。
不同的业务数据分实例存储
即便我们采用前缀的方式区分了存储的key,但是如果两个大量访问的业务都存储在同一个实例上,还是会对Redis的性能产生影响。因此最好不同的业务将数据存储在不同的Redis实例上。
数据保存时,设置合理的过期时间
如果过期时间不合理,要么Redis在不停的换入过期,要么内存很快撑爆服务器,对业务产生影响。
控制每个Redis实例的容量
Redis单实例的内存不要太大,通常建议时2-6GB。这样无论是RDB快照,还是主从集群的数据同步,速度都很快,不会阻塞正常的请求。
线上禁用命令
Redis是单线程处理请求,因此有些命令在线上使用有可能会长时间阻塞主线程。
- KEYS,按照键值对的key进行内存的匹配,需要对Redis的全局哈希表进行扫描,严重阻塞Redis主线程,可以用SCAN命令代替,分批返回符合条件的键值对。使用SCAN后要记得主动删除游标
- FLUSHALL,删除实例上所有的数据,如果数据量很大,严重阻塞Redis主线程。可以加上ASYNC选项,异步删除数据
- FLUSHDB,删除当前数据库里的数据,同样可能阻塞Redis主线程。可以加上ASYNC选项,异步删除数据
慎用MONITOR命令
monitor命令可以监控Redis的运行状态,但是它会把所有的操作返回都输出到输出缓存区域。如果操作很多,输出缓存会很快溢出,这对Redis的性能造成影响。
慎用全量操作命令
对于集合类型来说,如果要获取全部数据,一般不建议使用全量操纵指令,比如HGETALL,SMEMBERS。它们会对数据结构做全量扫描,集合类型数据较多的话,会阻塞Redis主线程。建议如下:
- 可以使用SSCAN,HSCAN分批返回集合的数据,减少阻塞
- 可以化整为零,将一个大的集合拆成多个小集合
- 如果存储的是多个业务的多个属性,而每次查询的时候也要返回这些属性,那么可以用String类型,将这些属性序列化后存储,使用时直接返回String即可。
常见问题
雪崩
当大量缓存数据在同一时刻过期(即缓存数据失效)或者Redis故障宕机时,此时如果有大量的请求访问Redis缓存数据则会导致大量请求会直接访问数据库(即直接压入数据库),导致数据库压力剧增,严重的情况会导致数据库直接宕机,致使整个系统崩溃,这就是缓存雪崩。 出现缓存雪崩主要是因为:
- Redis中大量缓存数据同一时间过期
- Redis故障宕机
解决方案:
- 过期时间设置随机值。这个方法最常用,数据的过期时间分散开来,就不会同时过期了
- 加互斥锁,然而在高并发的情况下,互斥锁会降低系统的吞吐能力。
- 双key策略,主key设置过期时间,副key不设置过期时间,两个key保存的值value是相同的,相当于副key是缓存数据的副本,当主key过期时可以直接返回副key的value(即缓存数据),而在主key更新时同时要更新主key和副key的缓存数据value。
- 针对Redis宕机,可以暂停对Redis的访问,直接返回错误;或者搭建高可用Redis集群,主节点宕机后可以自动切换节点。
穿透
用户访问的数据压根不存在Redis缓存中,也不存在数据库中,导致用户发送请求访问缓存时,缓存失效,便直接访问数据库也没有拿到数据,这样的话当有大量这样的请求打入时,数据库的压力会剧增,同样可能会导致数据库崩溃从而导致系统崩溃,这就是缓存穿透。
一般导致缓存穿透的情况有两种:
- 业务误操作(数据意外丢失)
- 黑客恶意攻击(故意访问一些不存在的数据)
解决方案:
- 设置缓存空值或者默认值,这种方案比较常用,查询不到数据的时候,可以在缓存里先放一个空值或者默认值,这样后续请求就会直接通过缓存返回了
- 非法请求的限制,入参前就校验是否合理,对非法请求进行拦截
- 设置可以访问的白名单。Redis的bitmaps类型可以定义一个可以访问的名单,如果访问的id不在bitmaps里,则不进行访问。
- 使用布隆过滤器,当数据写入数据库的时候,则更新布隆过滤器,当访问缓存数据不存在的时候,可以通过布隆过滤器尝试分析。布隆过滤器有一定的误判,查到数据库存在的数据有可能有一部分并不是真正存在的,但是检查不到的一定不在数据库。
击穿
大量用户请求同一个数据(即热点数据被频繁访问),刚好缓存中的热点数据过期,此时就会导致大量直接访问数据库,这样数据库很容易被高并发搞崩溃,击穿顾名思义针对一点不断打击,这就是缓存击穿。
解决方案:
- 加互斥锁,但是显然这种方式会导致吞吐能力下降
- 热点数据不设置过期时间,或者设计热点数据更新缓存,延长过期时间
缓存污染
缓存污染指的是缓存中一些只会被访问一次或者几次的的数据,被访问完后,再也不会被访问到,但这部分数据依然留存在缓存中,消耗缓存空间。缓存污染会随着数据的持续增加而逐渐显露,随着服务的不断运行,缓存中会存在大量的永远不会再次被访问的数据。缓存空间是有限的,如果缓存空间满了,再往缓存里写数据时就会有额外开销,影响Redis性能。
解决方案:
可以通过调整最大缓存值来避免内存太小影响性能,又要避免设置太大,影响同步。可以设置缓存容量为总数据量的15%-30%。
一致性问题
Redis作为缓存时读取数据时遇到的缓存失效后,在并发更新操作下,可以使用双写模式(即同时更新数据库和缓存),那么是先更新缓存,再更新数据库 还是 先更新数据库,再更新缓存呢?
- 先更新缓存,再更新数据库,线程1和线程2并发的进行更新数据操作,由于线程1在执行过程中存在卡顿情况,导致线程2执行完操作,才到线程1执行后面的操作。通过上图可以看到执行到最后的过程得到的结果是 数据库中的数据是数据1,缓存中的数据是数据2。 出现了缓存和数据库不一致的问题。
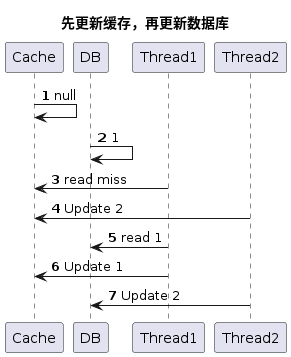
- 先更新数据库,再更新缓存,线程1和线程2并发的进行更新数据操作,同样由于线程1在执行过程中存在卡顿情况,导致线程2执行完操作,才到线程1执行后面的操作。过上图可以看到执行到最后的过程得到的结果是 数据库中的数据是数据2,缓存中的数据是数据1。 出现了缓存和数据库不一致的问题。
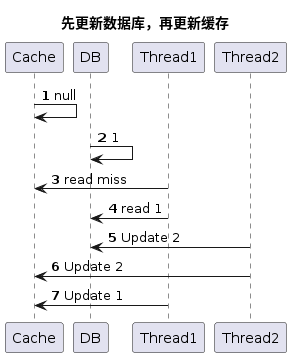
- 考虑删除缓存和更新数据库有失败的情况下, 情况会更复杂。
解决方法:
- 如果不要求数据具备实时性,能有一定的延迟的话,只需要在缓存中加上过期时间,这样数据最终总会一致。
- 如果对数据的一致性要求很高的话,则在更新缓存前加上分布式锁,保证同一时刻只允许一个线程进行操作,这样会避免了并发导致的问题,但是吞吐能力大大降低。
- 写入数据库如果失败的话,整个流程是肯定失败的,所有操作都应该回退。所以先写缓存的情况会更复杂。
- 写入数据库成功,但是删除/更新缓存失败,则应设置一定次数的重试,尝试更新缓存。如果重试次数超出,只能依赖缓存超期
- 先更新数据库再删除缓存的情况下,还可以利用binlog同步的机制,将数据更新到Redis里,可靠性更高
HotKey问题
在较短的时间内,海量请求访问一个Key,这样的Key就被称为HotKey。海量请求在较短的时间内,访问一个Key,势必会导致被访问的Redis服务器压力剧增,可能会将Redis服务器击垮,从而影响线上业务;HotKey过期的一瞬间,海量请求在较短的时间内,访问这个Key,因为Key过期了,这些请求会走到数据库,可能会将数据库击垮,从而影响线上业务。
治理Hotkey,需要解决从发现到通知Hotkey的产生,再到治理的过程。
如何发现Hotkey又可以拆解为两个子问题:如何知道每个Key的使用情况,以及如何统计。想要知道每个key的使用情况,可以在Redis客户端做埋点,也可以统一做一个Redis的代理,在代理层做埋点。前者管理不太方便,后者引入了新的故障点,需要综合取舍。统计的方式也有两种,一种是实时上报,业务系统的压力较小,但是上报数据很多;或者准实时上报,几类一定量或时间再上报,对业务自己有一定的内存压力。
发现Hotkey以后,由发现Hotkey的角色,通过MQ/RPC等方案触及客户端,告诉客户端Hotkey是什么,从而使得客户端可以处理Hotkey。
当客户端收到Hotkey以后,可以采用如下方式:
- 本地短时缓存Hotkey的数据,避免压力全部集中在Redis
- 将此Hotkey多分片存储到多个Redis实例,分散Hotkey的压力
此外,如果Redis采用主从+哨兵集群,则如果master节点挂了,就会自动切换一个slave为master,继续提供服务。这样也可以提高Redis的可用性。
事务里分布式锁失效
使用Redis做分布式锁还会遇到一种情况,就是在Transactional注解里使用分布式锁。可能代码会如下:
|
|
它的问题是事务是函数返回后才执行的,但是此前分布式锁已经释放了,另一个线程完全可以做出不同的业务逻辑,导致最后事务无法提交,分布式锁等于失效了。有时候这个问题隐藏得会很深,必须得留意。
为什么是Redisson而不是自己写分布式锁
说到Redis用作存储分布式锁,有时候我们会看到有人这么写:
|
|
这里的问题是,setnx和expire不是原子的。如果这个时候网断了,服务器挂了,都可能造成一个永久的锁。
还有人可能会这么写
|
|
return前没有释放锁,那么下次加锁只能等待expireTime超期了。
还有一种写法,使用getSet写的:
|
|
这段代码的问题是,如果getSet有多个终端同时请求,那么有可能最后加锁成功的线程的超时时间,跟jedis里的value并不一致。
还有一些问题跟释放锁有关系。比如:
|
|
有可能判断的时候锁是自己的,但是立刻过期了,然后被其它线程抢到了锁。那么最后unlock的时候,其实是解除了其它的锁。
还有锁超时释放了,但是业务没跑完,此时另一个线程会与当前业务形成竞争。这个最好是开启一个守护线程,业务没跑完的时候,就定期对锁做一些延长操作,可以避免提前释放。
就是由于有这么多问题,所以最好的办法,就是使用Redission。下边就是Redission的加锁方案:
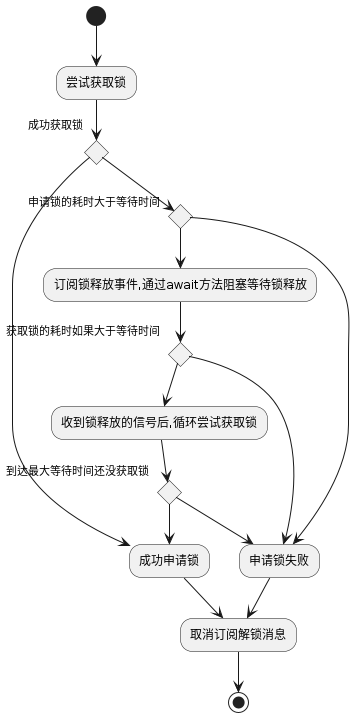
此外,它还有WatchDog,每10秒监控一次锁的状态,如果业务没有释放,则自动续期30秒,避免业务没完成时锁被释放导致业务问题。
释放锁的时候,它会注意锁的可重入性,如果全部的锁都释放了,就会删除锁,然后广播锁的删除事件,再取消WatchDog对锁的自动续期。通常来说分布式锁都应当采用Redisson来维护。