tcpdump排查现网问题两例
文章目录
【注意】最后更新于 March 30, 2023,文中内容可能已过时,请谨慎使用。
最近遇到了一件郁闷的事情,服务本身指标都正常,唯独搜索会超时,经过排查,非常明确是 ES 的 client 在发出 HTTP 请求以后,超时导致了用户结果异常。
本以为把问题反馈给运维就能找到问题,没想到运维一番查找,ES没有任何慢查询。这下问题就麻烦了,我服务 GC 正常,内存 CPU 都有不少余裕,pod 的 CPU 也没受到限制,网络流量正常,但是怎么证明我就是监控上上报的时候请求就发出去了,而不是在 client 里排队呢?
恰好同期也发生了一例 PG 查询缓慢的情况,我们超时信息是Druid的插件统计,得到偶尔耗时高达9-10秒,甚至25秒超时,而实际explain的时候扫描的行数却只有几十行的情况。这一次DBA也说没有发生慢查询,并且给出了 PG 的日志,显示请求后很快由请求方取消了请求,取消请求的时间与我服务里Druid超时的时间一致,建议我们排查Druid发出请求的池是否堵塞了。
还好我们有较为公正客观的标准,网络流量。所以处理也很简单,继续 tcpdump 走起!
由于这个流向是从服务器到 PG 服务器,因此我将接口流量导入到一个单独的环境,一天一千多请求,抓包处理很简单。采用的命令是 tcpdump -i eth0 -C 1000 'src host $currentIP and dst port 5432' -w debug.cap,-i的含义是采集 eth0 网卡上,从 currentIP 机器发出的,目标端口是 5432 的数据包,-C表示采集1G的数据。不需要应答是因为pg也没有及时应答,而且DBA也有明确的取消请求的时间点。
结果开始后没几分钟就抓到了问题请求:
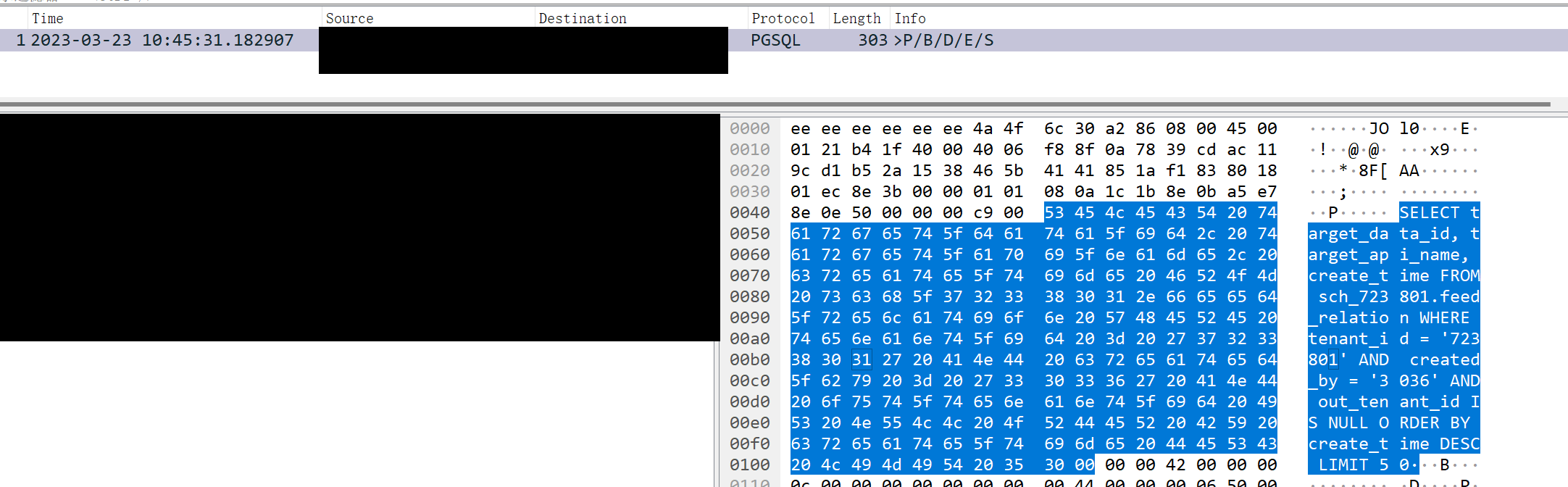
看图可知,当时10点45分31秒就已经发出了请求,但是DBA经查,该请求确实是10点45分56秒在PG被请求方取消了。后来经过DBA分析,原来问题是SQL语句的扫描数据行比较少,但是索引有问题,hints高达160万,超时的时候是PG从磁盘加载数据所致。因此当第二次,第三次请求的时候,通常只需要几十毫秒。因此优化索引后,问题消失了。
至于ES的问题,我们采用了 tcpdump -i any host $currentIP or $destIP -G 7200 -w /opt/tomcat/temp/tcp-%Y_%m%d_%H%M_%S.cap -s 512。这个命令是表示每7200秒记录一个文件,-s 表示抓到的包只保留512字节。最终我们抓到了如下的情况:
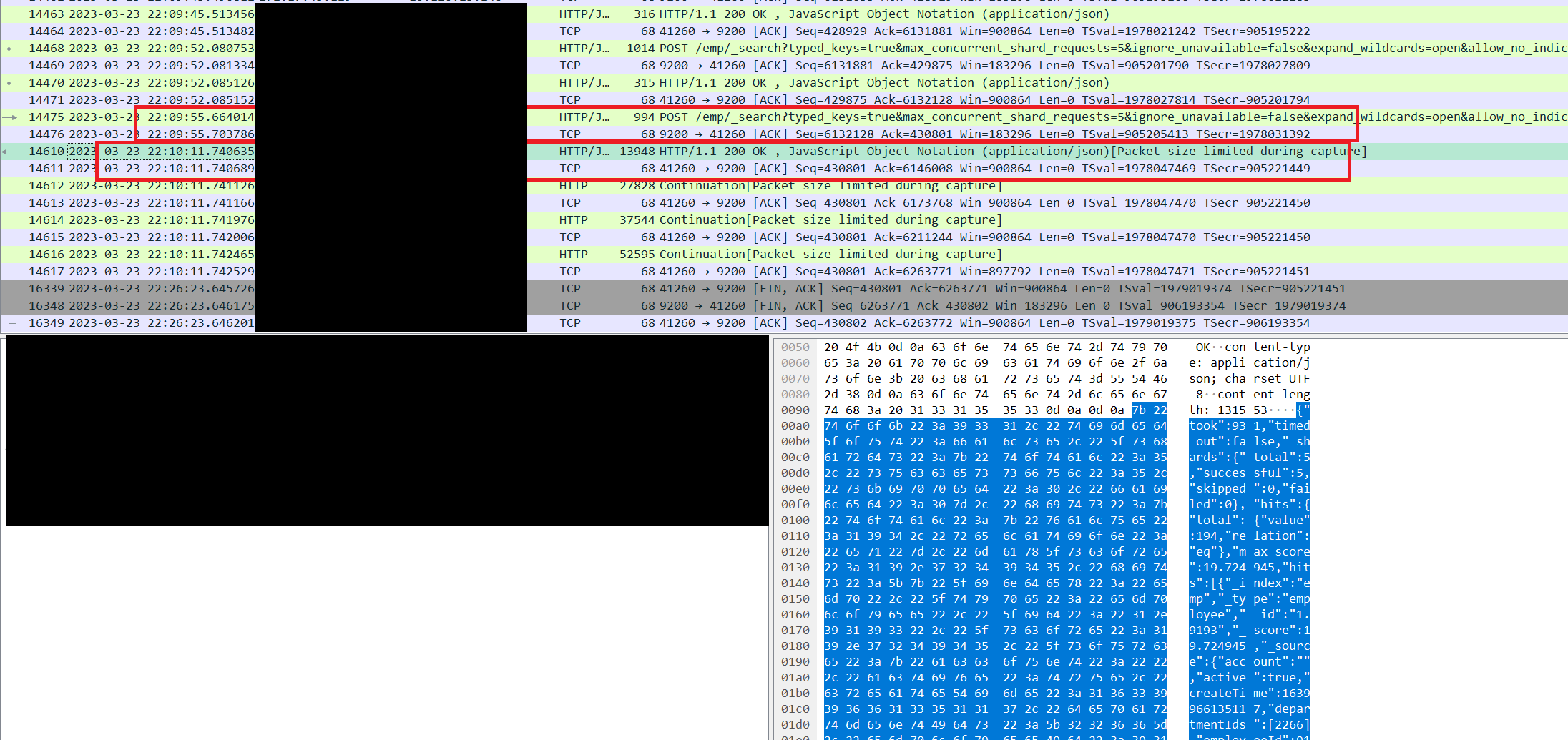
可以看到我们22点09分55秒已经发出了请求,但是ES确实是在22点10分11秒才返回结果。对于这样的结果,运维表示还要在宿主机上抓包去分析,希望能尽快发现到底是网络问题,还是ES本身的问题。